

De-mystifying Linear Regression Part 1
/
Introduction
In our last post, we discussed the scientific method and how it has been adopted for business use cases. While there are numerous variations of the scientific method in business, most philosophies take a similar approach to solving business problems and driving exploration. In this post, we will continue our discussion of data science and statistics tools and techniques and discuss linear regression as it applies to machine learning.
Definition
Before diving in, let's get some terminology out of the way. In the wild, it is possible that multiple terms could be used simultaneously for related, but different things. For example, in machine learning there are two major types of supervised learning problems, a regression problem and a classification problem. Regression refers to predicting a numerical value while classification refers to predicting a descriptor of the data or a classifier. Linear regression is a form of a regression model in machine learning, but there are other types of algorithms that can be used for regression learning such as Random Forest and Support Vector Machines. This writing will focus on the Simple Linear Regression algorithm and leave regression problem types to discuss at a later date.
Simple Linear Regression is really a mathematical formula that is meant to determine the relationship between two variable, an X or predictor and a Y or an outcome. Simple linear regression is called simple because it only has one predictor. Remember back to algebra in high school where as a student you were required to find the slope of a line in a cartesian plane. An example of a cartesian plane and some points are shown below.
Remember in a cartesian plane, x represents the horizontal axis and Y represents the vertical axis. In the plot shown, there are a series on points in the 1st quadrant. Back in algebra, often the problem would instruct a student to find the slope of this series of points or even a line. Remember, the formula for slope is given as:

With mx representing the slope and b representing the Y intercept (the Y point when X is 0). Remember, slope is simply:

Rise being how much the line changes on the y axis from point to point and run being how much the line changes on the x axis from point to point. So if we take the first two points (1,1) and (2,2), we see that the slope is:

Fitting a line to this data is simple because the slope is the same point to point so the regression line looks like:

Then if we say that the slope of the line is 1, what is the value of Y when X is 6?
If you said 6, then just did your first machine learning prediction. We have no reason to believe that Y would not be 6 if X was 6 based on the sample of data we have here. This was an overly simplistic example, lets look at another more complicated example.
Let's say we have a theoretical company whose service is heating and cooling repair. They perform house calls and can spend various amounts of time at a job depending on the complexity. Well they have collected some data from their past 19 service calls and would like to see if they can build a model to help them better quote jobs when customer's ask for costs. There could be a large amount of variables here for them to do that, but they noticed there seems to be a relationship between how long a job takes and how much it costs the customer. Since the actual cost is unknown until the technician diagnoses the problem, most of the time the customer service rep can estimate how much time a job will take based on the symptoms of the problem. Below is a table of the collected data:
## Job_Length_hours Cost_in_$$
## 1 1.0 100
## 2 3.0 280
## 3 6.0 610
## 4 0.5 50
## 5 0.5 80
## 6 2.0 200
## 7 2.0 200
## 8 3.0 302
## 9 5.0 498
## 10 1.0 111
## 11 1.5 145
## 12 1.0 100
## 13 2.0 198
## 14 3.0 320
## 15 4.0 406
## 16 2.0 250
## 17 1.0 160
## 18 1.0 80
## 19 1.5 170It is important to note that the cost is the response and the job length is the predictor. First thing we should do is plot these points (only showing the first quadrant of the Cartesian plane):
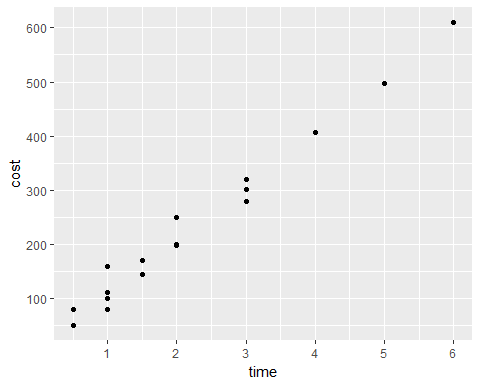
What is quickly noticed is that as time increases, so does the cost. However, we cannot just simply take the slope here because at some points there are different costs tied to the same amount of time. For example, if a job takes 3 hours, the costs have ranged from $280 to $320. So how would we go about modeling this?
First, let's define the simple linear regression equation as:

Y - The response value in the dataset.
β_0 - The value of Y when X is zero, the Y-intercept.
β_1 - The estimated slope coefficient.
X_i - the value of X at observation i.
ϵ_i - the error of the fitted regression model at observation i. In other words, error that is unexplained after a model is fit.
i=1,2....k - i is the number of observations in the dataset running in this case from 1 to 19.
Do not let the Greek letters intimidate you. These are just placeholders for coefficients that will be estimated.
Fitting the Simple Linear Regression Model
Now we will use something called least squares linear regression to calculate the model. Least squares is the most commonly used form of linear regression. It works by minimizing the sum of the squared deviations between the actual data and the model to estimate the coefficients. To fit a least squares linear regression model, the following steps will be performed:
1. Calculate the mean of the x's or predictor variable.
2. Calculate the mean of the y's or outcome variable.
3. Calculate the standard deviation of the x's or predictor variable.
4. Calculate the standard deviation of the y's or outcome variable.
5. Calculate the correlation coefficient of x and y.
6. Calculate the slope coefficient.
7. Calculate the y-intercept or coefficient.
8. Put it all together in a nice formula.
If you are reading those steps and do not know how to do any of them, that's ok, we will do them now!
Calculating the Mean (Statistical Average) of X and Y.
The mean is just the statistical average of a data set. Most people have experience calculating the mean and use it as an estimator for everything, which leads to a lot of unexpected events. First, to calculate the mean of x, we will use the formula:

This just means, we are going to add up all of the x's and divide by the number of observations. So adding up all of the values in Job_Length_hours column we get:
1+3+6+0.5+0.5+2+2+3+5+1+1.5+1+2+3+4+2+1+1+1.5 = 41
Next, we have 20 observations, so we divide the sum of x by the number of observations to get:

Notice, we do not want to round yet if we can help it. Also notice that the mean of x is denoted as ¯x.If the process is repeated for y, we have 224.2105. See if you can replicate the calculation to get y on your own. If you are using excel, you can just use the average function. I typically use R which uses the mean() function.
Calculating the Standard Deviation of X and Y.
The standard deviation is a little more complicated. Also notice we found the mean of x and y first; that is because we will need it as an input into the standard deviation. The standard deviation is found by:

What we are doing here is first calculating the variance under the square root and then taking the square root of that number to find the standard deviation. Note the standard deviation is a calculation thatr essentially finds the average distance of points from the mean or average. This is done by subtracting the mean of x from each actual observation, squaring it and then adding up all of those points. Then divide the sum of squares by n and take the square root. Let's do x together.
First, subtract the mean from each x point. Remember the mean is 2.157895. It might make sense to do this in a table to avoid confusion:
## time meanx Diff
## 1 1.0 2.157895 -1.1578947
## 2 3.0 2.157895 0.8421053
## 3 6.0 2.157895 3.8421053
## 4 0.5 2.157895 -1.6578947
## 5 0.5 2.157895 -1.6578947
## 6 2.0 2.157895 -0.1578947
## 7 2.0 2.157895 -0.1578947
## 8 3.0 2.157895 0.8421053
## 9 5.0 2.157895 2.8421053
## 10 1.0 2.157895 -1.1578947
## 11 1.5 2.157895 -0.6578947
## 12 1.0 2.157895 -1.1578947
## 13 2.0 2.157895 -0.1578947
## 14 3.0 2.157895 0.8421053
## 15 4.0 2.157895 1.8421053
## 16 2.0 2.157895 -0.1578947
## 17 1.0 2.157895 -1.1578947
## 18 1.0 2.157895 -1.1578947
## 19 1.5 2.157895 -0.6578947Taking the first value and performing the calculation 1-2.157895 = -1.1578947.This operation is repeated for each value of job time. Next step is to take the values we calculated in the new column and square them.
## time meanx Diff Squares
## 1 1.0 2.157895 -1.1578947 1.34072022
## 2 3.0 2.157895 0.8421053 0.70914127
## 3 6.0 2.157895 3.8421053 14.76177285
## 4 0.5 2.157895 -1.6578947 2.74861496
## 5 0.5 2.157895 -1.6578947 2.74861496
## 6 2.0 2.157895 -0.1578947 0.02493075
## 7 2.0 2.157895 -0.1578947 0.02493075
## 8 3.0 2.157895 0.8421053 0.70914127
## 9 5.0 2.157895 2.8421053 8.07756233
## 10 1.0 2.157895 -1.1578947 1.34072022
## 11 1.5 2.157895 -0.6578947 0.43282548
## 12 1.0 2.157895 -1.1578947 1.34072022
## 13 2.0 2.157895 -0.1578947 0.02493075
## 14 3.0 2.157895 0.8421053 0.70914127
## 15 4.0 2.157895 1.8421053 3.39335180
## 16 2.0 2.157895 -0.1578947 0.02493075
## 17 1.0 2.157895 -1.1578947 1.34072022
## 18 1.0 2.157895 -1.1578947 1.34072022
## 19 1.5 2.157895 -0.6578947 0.43282548For example, take the first calculated value and multiply it by itself: -1.1578947*-1.1578947 = 1.34072022. Repeat this for all values calculated in the Diff column.
Next, sum up all values in the squares column, divide by n-1 (18) and take the square root:
## [1] 1.518887
Summing the squares column gives 41.52632 (feel free to check). Then dividing 41.52632 by 18 gives:

Last taking the square root of this gives:

That's it! Standard deviation has been calculated. Repeating for y gives 150.3066.
Calculating the Correlation Coefficient of X and Y
The correlation coefficient is meant to measure the linear relationship by x and y. The value falls between -1 and 1. If the value is at or around 0, there is no linear relationship. If the value is closer to 1 or -1, then there is a strong positive or negative relationship or slope. Calculating this coefficient uses the mean and standard deviation from the previous exercises.
The first step is the same as in calculating standard deviation, the mean is subtracted from each value of x and y, so we will skip that since it was done for standard deviation. Since we have that value, next we are going to divide by the standard deviation to get a standardized value.
## time meanx Diff Squares Stand_Dev Standard_Value
## 1 1.0 2.157895 -1.1578947 1.34072022 1.518887 -0.7623311
## 2 3.0 2.157895 0.8421053 0.70914127 1.518887 0.5544226
## 3 6.0 2.157895 3.8421053 14.76177285 1.518887 2.5295532
## 4 0.5 2.157895 -1.6578947 2.74861496 1.518887 -1.0915195
## 5 0.5 2.157895 -1.6578947 2.74861496 1.518887 -1.0915195
## 6 2.0 2.157895 -0.1578947 0.02493075 1.518887 -0.1039542
## 7 2.0 2.157895 -0.1578947 0.02493075 1.518887 -0.1039542
## 8 3.0 2.157895 0.8421053 0.70914127 1.518887 0.5544226
## 9 5.0 2.157895 2.8421053 8.07756233 1.518887 1.8711763
## 10 1.0 2.157895 -1.1578947 1.34072022 1.518887 -0.7623311
## 11 1.5 2.157895 -0.6578947 0.43282548 1.518887 -0.4331427
## 12 1.0 2.157895 -1.1578947 1.34072022 1.518887 -0.7623311
## 13 2.0 2.157895 -0.1578947 0.02493075 1.518887 -0.1039542
## 14 3.0 2.157895 0.8421053 0.70914127 1.518887 0.5544226
## 15 4.0 2.157895 1.8421053 3.39335180 1.518887 1.2127995
## 16 2.0 2.157895 -0.1578947 0.02493075 1.518887 -0.1039542
## 17 1.0 2.157895 -1.1578947 1.34072022 1.518887 -0.7623311
## 18 1.0 2.157895 -1.1578947 1.34072022 1.518887 -0.7623311
## 19 1.5 2.157895 -0.6578947 0.43282548 1.518887 -0.4331427Walking through the first x value, subtract the mean from x, then divide the difference by the standard deviation to get the standard value.

Repeat this for every value of x. Before moving on, it is important to calculate the y values as well.
## Standard_Value_X Standard_Value_Y
## 1 -0.7623311 -0.8263812
## 2 0.5544226 0.3711712
## 3 2.5295532 2.5666841
## 4 -1.0915195 -1.1590347
## 5 -1.0915195 -0.9594426
## 6 -0.1039542 -0.1610743
## 7 -0.1039542 -0.1610743
## 8 0.5544226 0.5175388
## 9 1.8711763 1.8215403
## 10 -0.7623311 -0.7531975
## 11 -0.4331427 -0.5269931
## 12 -0.7623311 -0.8263812
## 13 -0.1039542 -0.1743804
## 14 0.5544226 0.6372940
## 15 1.2127995 1.2094580
## 16 -0.1039542 0.1715792
## 17 -0.7623311 -0.4271971
## 18 -0.7623311 -0.9594426
## 19 -0.4331427 -0.3606664Now we have the standard values of x and y in a table. Next, we multiply the standard values of each x and each y.
## Standard_Value_X Standard_Value_Y Product
## 1 -0.7623311 -0.8263812 0.62997610
## 2 0.5544226 0.3711712 0.20578572
## 3 2.5295532 2.5666841 6.49256380
## 4 -1.0915195 -1.1590347 1.26510898
## 5 -1.0915195 -0.9594426 1.04725034
## 6 -0.1039542 -0.1610743 0.01674436
## 7 -0.1039542 -0.1610743 0.01674436
## 8 0.5544226 0.5175388 0.28693519
## 9 1.8711763 1.8215403 3.40842309
## 10 -0.7623311 -0.7531975 0.57418585
## 11 -0.4331427 -0.5269931 0.22826320
## 12 -0.7623311 -0.8263812 0.62997610
## 13 -0.1039542 -0.1743804 0.01812759
## 14 0.5544226 0.6372940 0.35333020
## 15 1.2127995 1.2094580 1.46682995
## 16 -0.1039542 0.1715792 -0.01783638
## 17 -0.7623311 -0.4271971 0.32566561
## 18 -0.7623311 -0.9594426 0.73141293
## 19 -0.4331427 -0.3606664 0.15622000Taking the first entry, multiply -0.7623311*-0.8263812 = 0.62997610. Repeat for each value of X. The last step is to sum up the new column of products and divide by n-1. Summing the products gives 17.83571. Dividing that by 18 yields a correlation coefficient of 0.9908726.This tells us our data set has a really strong positive correlation.
Calculate the Slope Coefficient
Whewwwww...Almost there. The slope coefficient or β_1 is found by multiplying the correlation coefficient by the ratio of standard deviations of y and x or:
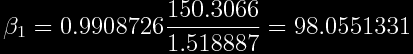
That was not too bad, let's move on to find the y intercept or β_0.
Calculate the Y intercept
The y intercept or β_0 is found by:

So that is the mean of y minus the product of the slope coefficient and mean of x:
224.2105263 - 98.0551331 * 2.1578947 = 12.6178707
Assemble the Linear Equation
To assemble the linear equation, plug in the values for β_0 and β_1. Which is:

This is the formula that can now be used to predict other values. Plugging in all of the current values for X will give the fitted values of the model so we can evaluate model fit.
For example, the first value of x is 1, so we have:
Y_1=12.61787+98.05513*1=110.67300
Repeating this for all values of x, provides the fitted values of the model. Now let's plot our model against our data to see the fit:

Conclusion
Since this post is already running long, we will leave it there. In our next post, we will continue this concept and assess the fit of the model and start predicting some future values. We will also discuss the pro's and con's of simple linear regression.

